
目的
帮助新手快速完成Hadoop分布式安装,使用新手对Hadoop分布式文件系统(HDFS)和Map-Reduce框架有所体会
平台环境
VMware® Workstation 14 Pro、CentOS7
所需软件
JDK1.8.0_181、ssh、pdsh
Hadoop集群的准备工作
本人用3台虚拟机来安装,分别为
master(主),IP:192.168.1.190
slave1(从1),IP:192.168.1.191
slave2(从2),IP:192.168.1.192
系统安装(3台centos7系统虚拟机)
先在1台虚拟机上安装centos系统,然后再通过克隆出来另外2台,每台虚拟机内存最少要1G,不然可能有点卡,3台虚拟机上都需要安装前面的软件,每台虚拟机上都要配置静态IP,和主机名(hostname)
设置虚拟机的连接模式
为了模拟真实主机,虚拟机使用了桥接模式连接网络,和我们的电脑主机共同在一个网络段,方便通过ssh连接管理,设置方法如下:
点VMware菜单中的“编辑”-->"虚拟网络编辑器"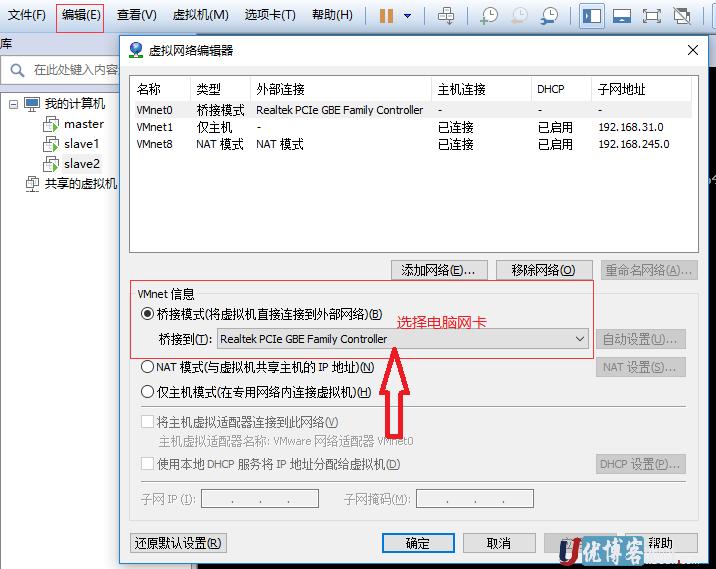
桥接到中选择电脑的网卡,保存配置静态IP
先通过下面命令查看当前网卡名称:[hadoop@master hadoop-3.1.1]$ ifconfig -a ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.1.190 netmask 255.255.255.0 broadcast 192.168.1.255 inet6 fe80::6ea5:171b:e3af:8b2 prefixlen 64 scopeid 0x20 ether 00:0c:29:2f:19:b8 txqueuelen 1000 (Ethernet) RX packets 106268 bytes 26026510 (24.8 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 54369 bytes 9182638 (8.7 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0en开头的就是网卡,再输入面命令修改ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33配置如下,请修改有注释部分即可:
#网络类型,以太网 TYPE=Ethernet #静态IP BOOTPROTO=static PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=none DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=9dfcdfb3-4b4b-49cd-b953-0bed580e95fc DEVICE=ens33 #开机启动 ONBOOT=yes IPV6_PRIVACY=no #IP地址,和电脑是同一网络即可 IPADDR=192.168.1.190 PREFIX=24 #网关 GATEWAY=192.168.1.1 #DNS DNS1=202.96.134.133 DNS2=202.96.128.166 PEERDNS=no ZONE=public修改主机名称
输入如下命令:vi /etc/hostname把localhost改为下面内容
master.localdomain需要重启系统生效
另外两个从节点分别为 slave1.localdomain和slave2.localdomain主机名映射ip
编辑/etc/hosts文件,添加如下内容,需要192.168.1.190 master 192.168.1.191 slave1 192.168.1.192 slave2软件安装
yum install ssh yum install pdshJDK请自行安装,并配置好JAVA_HOME,不会的请自行搜索,一般centos都会自带JDK,但是最好从官方网站下载JDK
JDK安装请参考《CentOS7安装JDK环境》
添加hadoop用户
adduser hadoop passwd hadoop #输入两次密码关闭防火墙
systemctl stop firewalld
systemctl disable firewalld免密SSH设置
免密设置是在hadoop用户下进行,需要切换hadoop用户
su - hadoop
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
3台虚拟机都执行完成后再执行下面命令
ssh-copy-id -i ~/.ssh/id_rsa.pub master
#提示Are you sure you want to continue connecting (yes/no)?时输入yes,回车
#再输入hadoop用户密码
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
#提示Are you sure you want to continue connecting (yes/no)?时输入yes,回车
#再输入hadoop用户密码
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
#提示Are you sure you want to continue connecting (yes/no)?时输入yes,回车
#再输入hadoop用户密码
chmod 0600 ~/.ssh/authorized_keys所有虚拟机都执行一次,然后测试一下能不能不需要密码相互连接
[hadoop@master ~]$ ssh slave1
Last login: Mon Sep 3 16:22:39 2018
[hadoop@slave1 ~]$ 已经成功从master连接到slave1,然后exit退出
分布式模式安装
下载hadoop3.1.1,链接:hadoop 3.1.1
//进入工作目录
cd /usr/local
//下载hadoop
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
//解压
tar zxvf hadoop-3.1.1/hadoop-3.1.1.tar.gz
//进入hadoop根目录
cd hadoop-3.1.1编辑 etc/hadoop/hadoop-env.sh文件,至少需要将JAVA_HOME设置为Java安装根路径。
# 设置JAVA_HOME,本人的目录是:/usr/local/jdk1.8.0_181
export JAVA_HOME=/usr/local/jdk1.8.0_181尝试如下命令:
bin/hadoop如果jdk环境没有问题,将会显示hadoop 脚本的使用文档。
配置文件修改
修改core-site.xml文件,3个系统都必须修改该文件
vi etc/hadoop/core-site.xml内容如下:
fs.defaultFS hdfs://master:9000 hadoop.tmp.dir /usr/local/hadoop-3.1.1/data/tmp修改hdfs-site.xml文件,只需修改master节点
vi etc/hadoop/hdfs-site.xml内容如下:
dfs.namenode.http-address master:50070 dfs.namenode.name.dir /usr/local/hadoop-3.1.1/data/name dfs.replication 2 dfs.datanode.data.dir /usr/local/hadoop-3.1.1/data/data修改mapred-site.xml文件,只需修改master节点
vi etc/hadoop/mapred-site.xml内容如下:
mapreduce.framework.name yarn修改workers文件,只需修改master节点
vi etc/hadoop/workers内容如下,为3个机器的主机名,每个一行:
master slave1 slave2修改yarn-site.xml文件,只需修改master节点
vi etc/hadoop/yarn-site.xml内容如下:
yarn.resourcemanager.hostname master yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.nodemanager.resource.cpu-vcores 1启动Hadoop
./sbin/start-all.sh 输入jps查看运行结果如下表示启动成功
master中输入jps显示结果:
[hadoop@master hadoop-3.1.1]$ jps
20224 DataNode
20771 NodeManager
20104 NameNode
20408 SecondaryNameNode
21116 Jps
20653 ResourceManager其它两个slave节点显示结果:
[hadoop@slave1 ~]$ jps
15312 DataNode
15425 NodeManager
15541 Jps
在浏览器中输入http://192.168.1.190:50070,界面如下:
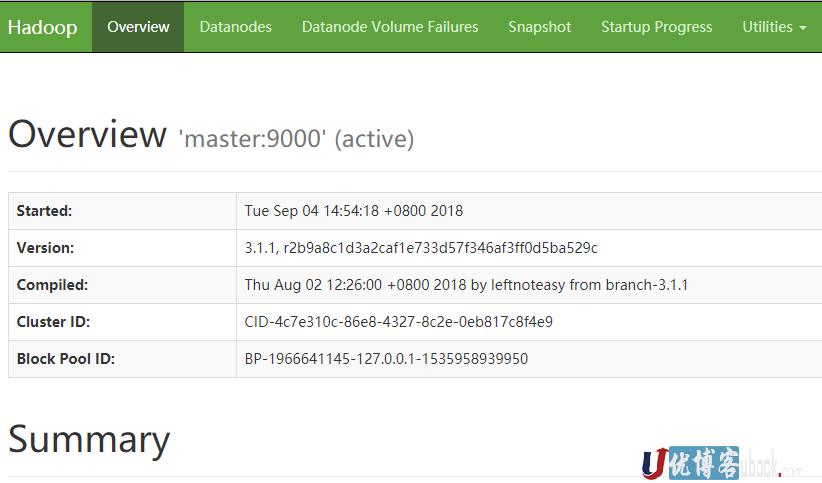
hadoop分布式安装完成!