
目的
帮助新手快速完成单机上的Hadoop安装与使用,使用新手对Hadoop分布式文件系统(HDFS)和Map-Reduce框架有所体会,比如在HDFS上运行示例程序或简单作业等
平台环境
VMware® Workstation 14 Pro、CentOS7
所需软件
JDK1.8.0_181、ssh、pdsh
安装软件
yum install ssh
yum install pdsh下载Hadoop 3.1.1
下载链接:hadoop 3.1.1
//进入工作目录
cd /usr/local
//下载hadoop
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
//解压
tar zxvf hadoop-3.1.1/hadoop-3.1.1.tar.gz
//进入hadoop根目录
cd hadoop-3.1.1Hadoop集群的准备工作
编辑 etc/hadoop/hadoop-env.sh文件,至少需要将JAVA_HOME设置为Java安装根路径。
# 设置JAVA_HOME,本人的目录是:/usr/local/jdk1.8.0_181
export JAVA_HOME=/usr/local/jdk1.8.0_181尝试如下命令:
bin/hadoop如果jdk环境没有问题,将会显示hadoop 脚本的使用文档。
现在你可以用以下三种支持的模式中的一种启动Hadoop集群:
单机模式
伪分布式模式
完全分布式模式
单机模式
默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。这对调试非常有帮助。
下面的实例将已解压的 etc/hadoop目录拷贝作为输入,查找并显示匹配给定正则表达式的条目。输出写入到指定的output目录。
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar grep input output 'dfs[a-z.]+'
cat output/*如果一切正常,将会输出
1 dfsadmin伪分布式模式
Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行。
配置
编辑etc/hadoop/core-site.xml文件,configuration内容如下:
fs.defaultFS
hdfs://localhost:9000
编辑etc/hadoop/hdfs-site.xml文件,configuration内容如下:
dfs.replication
1
免密SSH设置
输入如下命令确认可以免密登录ssh
ssh localhost如果不输入密码不可以登录成功,则执行如下命令:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys执行
本地运行MapReduce
格式化一个新的分布式文件系统
bin/hdfs namenode -format运行NameNode 守护进程和DataNode 守护进程
sbin/start-dfs.shhadoop log输出目录为$HADOOP_LOG_DIR,默认目录是:$HADOOP_HOME/logs
这里是按照官方文档来执行的,会报如下错误:Starting namenodes on [localhost.localdomain] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting secondary namenodes [localhost.localdomain] ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.意思是说尝试以root用户来操作hdfs namenode、hdfs datanode、hdfs secondarynamenode,但是未定义HDFS_NAMENODE_USER、HDFS_DATANODE_USER、HDFS_SECONDARYNAMENODE_USER,解决办法如下:
编辑etc/hadoop/hadoop-env.sh文件,在末尾添加如下定义,export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root再次执行sbin/start-dfs.sh,输出下面信息则表示运行成功:
Starting namenodes on [localhost.localdomain] 上一次登录:五 8月 31 17:48:26 CST 2018pts/0 上 Starting datanodes 上一次登录:六 9月 1 18:48:12 CST 2018pts/0 上 Starting secondary namenodes [localhost.localdomain] 上一次登录:六 9月 1 18:48:14 CST 2018pts/0 上执行jps可以看到namenode进程:
[root@localhost hadoop-3.1.1]# jps 3040 NameNode 3425 SecondaryNameNode如果没有看到上面两个进程,则可以尝试重新执行格式化命令:bin/hdfs namenode -format
通过浏览器打开http://localhost:9870可以看到如下界面:
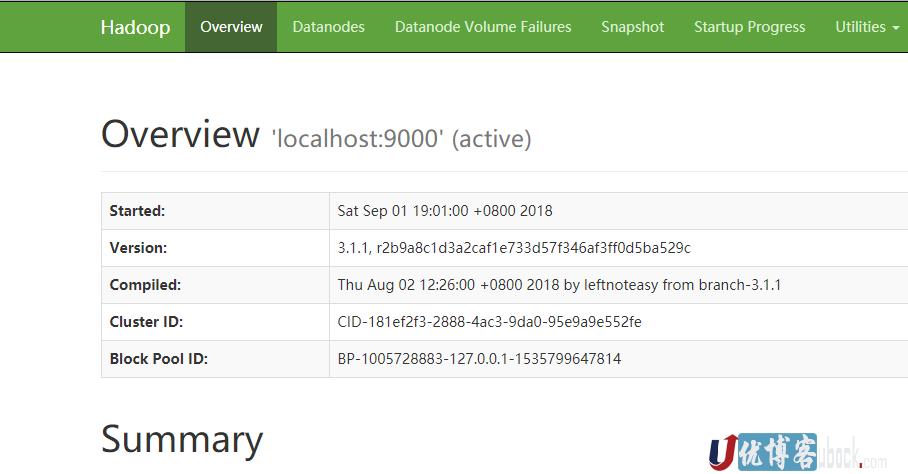
创建HDFS目录
bin/hdfs dfs -mkdir /user bin/hdfs dfs -mkdir /user/root复制输入文件到分页式系统
bin/hdfs dfs -mkdir input bin/hdfs dfs -put etc/hadoop/*.xml input运行MapReduce示例
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar grep input output 'dfs[a-z.]+'把文件从分页式系统中复制到本地再检查输出文件
bin/hdfs dfs -get output output cat output/*或者直接在分布式系统中检查:
bin/hdfs dfs -cat output/*停止守护进程
sbin/stop-dfs.sh
单节点YARN
配置下面的参数,按照官方文档编辑下面两个文件
vi etc/hadoop/mapred-site.xmlmapreduce.framework.name yarn mapreduce.application.classpath $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
vi etc/hadoop/yarn-site.xmlyarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME运行ResourceManager和NodeManager守护进程
sbin/start-yarn.sh按照官方的配置启动时会报下面错误信息:
Starting resourcemanagers on [] ERROR: Attempting to operate on yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation. Starting nodemanagers ERROR: Attempting to operate on yarn nodemanager as root ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.意思是尝试以root用户操作yarn resourcemanageer和yarn nodemanager,但是YARN_RESOURCEMANAGER_USER和YARN_NODEMANAGER_USER未定义,解决办法和前面一样,编辑etc/hadoop/hadoop-env.sh,在末尾添加如下定义:
export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root再运行会继续报下面错误:
localhost: ERROR: Cannot set priority of resourcemanager process 8197错误信息很少,不足以解决问题,可以查看log信息如下:
cat logs/hadoop-root-resourcemanager-localhost.localdomain.log 2018-09-01 20:07:26,123 FATAL org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Error starting ResourceManager java.lang.ExceptionInInitializerError at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceInit(ResourceManager.java:259) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1492) Caused by: java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal to have multiple roots (start tag in epilog?). at [row,col,system-id]: [27,2,"file:/usr/local/hadoop-3.1.1/etc/hadoop/mapred-site.xml"] at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3003) at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2926) at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2806) at org.apache.hadoop.conf.Configuration.get(Configuration.java:1460) at org.apache.hadoop.yarn.factory.providers.RecordFactoryProvider.getRecordFactory(RecordFactoryProvider.java:49) at org.apache.hadoop.yarn.server.resourcemanager.RMServerUtils.(RMServerUtils.java:104) ... 3 more Caused by: com.ctc.wstx.exc.WstxParsingException: Illegal to have multiple roots (start tag in epilog?). at [row,col,system-id]: [27,2,"file:/usr/local/hadoop-3.1.1/etc/hadoop/mapred-site.xml"] at com.ctc.wstx.sr.StreamScanner.constructWfcException(StreamScanner.java:621) at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:491) at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:475) at com.ctc.wstx.sr.BasicStreamReader.handleExtraRoot(BasicStreamReader.java:2242) at com.ctc.wstx.sr.BasicStreamReader.nextFromProlog(BasicStreamReader.java:2156) at com.ctc.wstx.sr.BasicStreamReader.closeContentTree(BasicStreamReader.java:2991) at com.ctc.wstx.sr.BasicStreamReader.nextFromTree(BasicStreamReader.java:2734) at com.ctc.wstx.sr.BasicStreamReader.next(BasicStreamReader.java:1123) at org.apache.hadoop.conf.Configuration$Parser.parseNext(Configuration.java:3257) at org.apache.hadoop.conf.Configuration$Parser.parse(Configuration.java:3063) at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2986) ... 8 more是说配置文件中有多个根标签,解决办法是编辑etc/hadoop/mapred-site.xml文件,合并两个configuration标签如下:
mapreduce.framework.name yarn mapreduce.application.classpath $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
此时再运行则没有异常,输入jps命令可以看到多出下面两个进程:8980 ResourceManager 9133 NodeManager浏览器打开http://localhost:8088,会看到如下界面

停止yarn进程
sbin/stop-yarn.sh
到此Hadoop3.1.1单节点集群安装已经全部完成,全分布式环境搭建请参考《新手Hadoop3.1.1分布式集群安装教程》
参考官方文档:单节点集群